ISC23 Project Poster: SCALABLE: Scalable Lattice-Boltzmann Leaps to Exascale
Poster in institute repository: http://dx.doi.org/10.34734/FZJ-2023-04519
At the ISC High Performance Conference 2023 a little while ago, we presented a project poster on the SCALABLE project, embedded at the end of this post. The work was also presented as a paper at the the Computing Frontiers 2023 conference previously.
Overview
 SCALABLE is a EuroHPC-JU-funded project, which aims to improve scalability and
energy efficiency for a selection of CFD solvers based on Lattice Boltzmann Methods (LBM) on
pre-exascale systems and preparing them for the upcoming European exascale systems.
SCALABLE is a EuroHPC-JU-funded project, which aims to improve scalability and
energy efficiency for a selection of CFD solvers based on Lattice Boltzmann Methods (LBM) on
pre-exascale systems and preparing them for the upcoming European exascale systems.
In the project, we are working on two LBM-based solvers, waLBerla and LaBS. WaLBerla can achieve excellent performance because of its unique, architecture-specific automatic generation of optimized compute kernels, together with carefully designed parallel data structures. However, it lacks some industrial capabilities, such as the ability to handle complex geometries and boundary conditions. On the other hand, the industrial CFD software LaBS already has such industrial capabilities at a proven high level of maturity, but does not achieve the performance of waLBerla.
 The goal of the SCALABLE project is to transfer the leading-edge performance technology of waLBerla
to LaBS, while at the same time transferring the industrial capabilities of LaBS to waLBerla. The
project also tries to improve the energy efficiency of both solvers by tuning the applications
dynamically. Some of the methods of dynamic tuning which are used were developed in the Horizon 2020
project READEX.
The goal of the SCALABLE project is to transfer the leading-edge performance technology of waLBerla
to LaBS, while at the same time transferring the industrial capabilities of LaBS to waLBerla. The
project also tries to improve the energy efficiency of both solvers by tuning the applications
dynamically. Some of the methods of dynamic tuning which are used were developed in the Horizon 2020
project READEX.
In order to validate the efforts of the project, we have chosen a suite of test cases, reflecting the interests of our academic and industrial partners. To provide a quick verification of validity, we have picked a convective vortex test case and a turbulent channel test case. The convective vortex test case allows us to validate the convergence of our simulations while the turbulent channel test case allows us to validate our simulations in the region of turbulent flow.
As a test to showcase the industrial application, we have chosen the Lagoon landing gear test case. During the landing phase of an aircraft, the landing gear is an important source of noise and produces a non-trivial turbulent flow. The test case is a simplified model of a landing gear with an already existing extensive database of experimental results for both aerodynamics and acoustics. The simple geometry and an existing large experimental database make the use case an attractive candidate to test and benchmark the performance of the new framework. More information on the Lagoon landing gear can be found here.
Performance Analysis and Optimization
As is often the case with performance optimization, we use various tools to measure and analyze the performance of the solvers. In particular, we use tools like Score-P and Extrae for general profiling and vendor-specific tools for the GPU profiling, like NVIDIA Nsight Systems and Omniperf.
Guided by the information in the profiles, a host of different techniques have been used in optimizing the performance of the solvers. Some of the techniques that we have used are:
- Optimizing MPI Communication by synchronizing communication and computation
- Using task graphs on GPU for more fine-grained parallelism
- Using CUDA streams for overlapping communication and computation
- SIMD vectorization of selected compute kernels
- MPI-OpenMP hybrid parallelization to reduce communication overheads
We also presented a poster at ISC23 about the techniques we used with CUDA task graphs for our simulations. Stay tuned for the blog post about the work done in that project!
With the help of techniques mentioned above, we have been able to appreciably improve the performance of both LaBS and waLBerla. In the figures below, we demonstrate strong scaling of both waLBerla and LaBS on the Lagoon landing gear test case. The plots show that the performance of waLBerla solvers is respectable as compared to ideal scaling for upto 256 (28) GPUs but falls off at higher GPU counts. For LaBS, the simulation is performed on a CPU cluster, and the performance is respectable for upto 2048 (211) cores. Increasing this performance will be addressed in the future work of the project.
 |
 |
| The waLBerla test case was run on the Booster module of the JUWELS supercomputer at JSC and contains approximately 277 million fluid nodes. It can scale well up to 1024 A100 GPUs, corresponding to approximately 2 million fluid nodes per GPU. | The LaBS simulation was executed on the CPU partition of the Karolina supercomputer at IT4I. The test case contains approximately 277 million fluid nodes and can scale acceptably up to 10 240 cores, corresponding to approximately 30 thousand fluid nodes per core. |
Energy Efficiency
As mentioned above, apart from the performance goals, the project is also concerned with energy efficiency of the solvers. For non-accelerated applications (running primarily on CPU), energy consumption can often be fine-tuned by using dynamic tuning principles, like the ones developed in the READEX project. The technique can exploit the dynamic behavior of different phases of applications, selecting best-fitting CPU clock frequencies to the phases and thereby improve the energy efficiency. For GPU-based applications, currently, only static tuning facilities can be used as available through the GPU drivers.
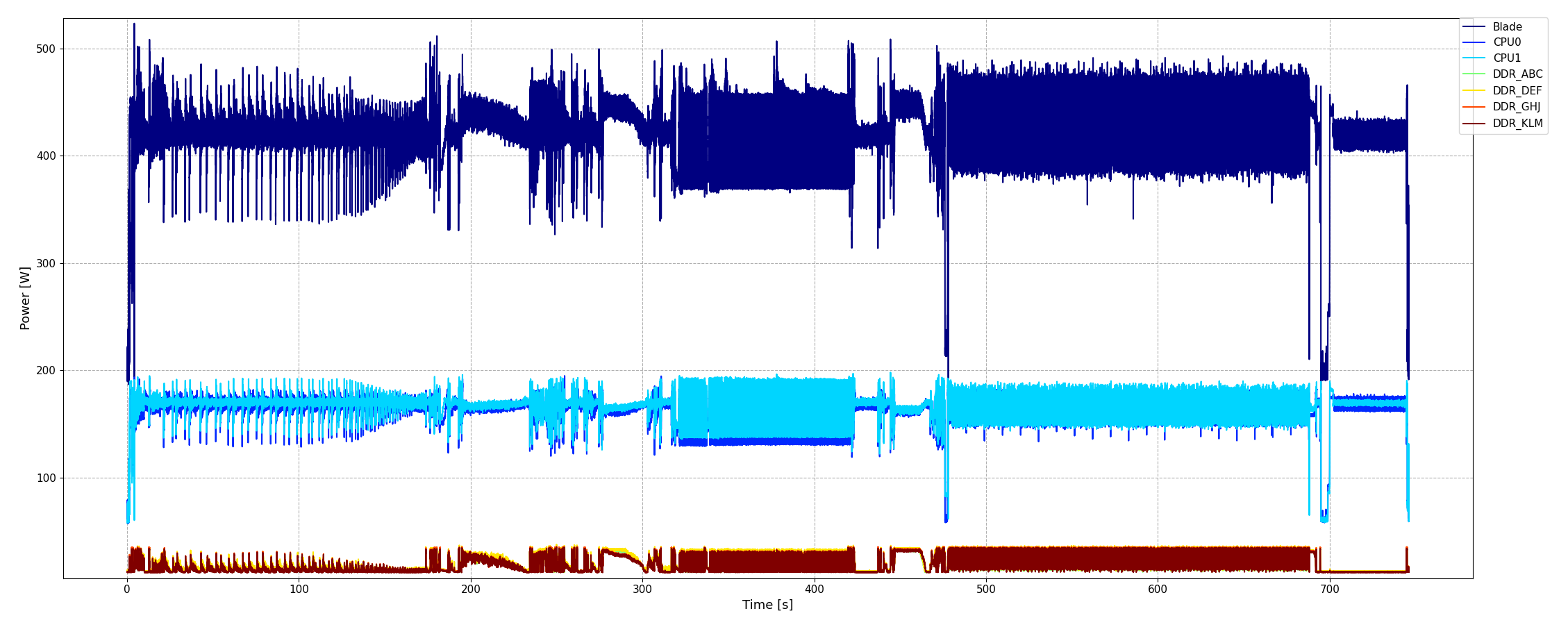
In SCALABLE, the MERIC runtime system, developed as a part of READEX, is used to scale CPU core and uncore frequencies to fit the executed phase of the applications. The figure below shows the effect of employing MERIC on LaBS, executing the Lagoon test case. Major energy savings can be obtained over the full compute node with negligible performance loss. One can see how the frequency of the CPU cores is dynamically adjusted to the current phase of the application.
The figures below show waLBerla running a GPU version of the Lagoon test case. The left figure shows the effect of adjusting the GPU core frequency on both the runtime and the energy consumption of the system. The right figure shows the effect of adjusting the CPU core frequency on both the runtime and the energy consumption of the system. As expected, the scaling of GPU core frequency has a major impact on the runtime and energy consumption since the majority of the work of the application is done on the GPU. Selecting 1095 MHz results in a small 2.2% runtime increase, but in a severe 19.8% energy reduction! One can also see that scaling of the CPU core frequency does not bring any additional savings in this case since the GPU is the main consumer of energy.
 |
 |
| Runtime and energy consumption of waLBerla (GPU) over various GPU multiprocessor frequencies. | Runtime and energy consumption of waLBerla (GPU) over various CPU core frequencies. |
Future Work
In the second half of the project, we are porting our applications to newer hardware like the NVIDIA H100, AMD MI250 GPUs, and ARM/RISC-V architectures. We are also improving the scalability of our solvers to scale to larger parts of pre-exascale systems. Stay tuned!
This project has received funding from the European High-Performance Computing Joint Undertaking Joint Undertaking (JU) under grant agreement No 956000. The JU receives support from the European Union’s Horizon 2020 research and innovation program and France, Germany, Czech Republic.